
Transformer笔记2 —— VIT
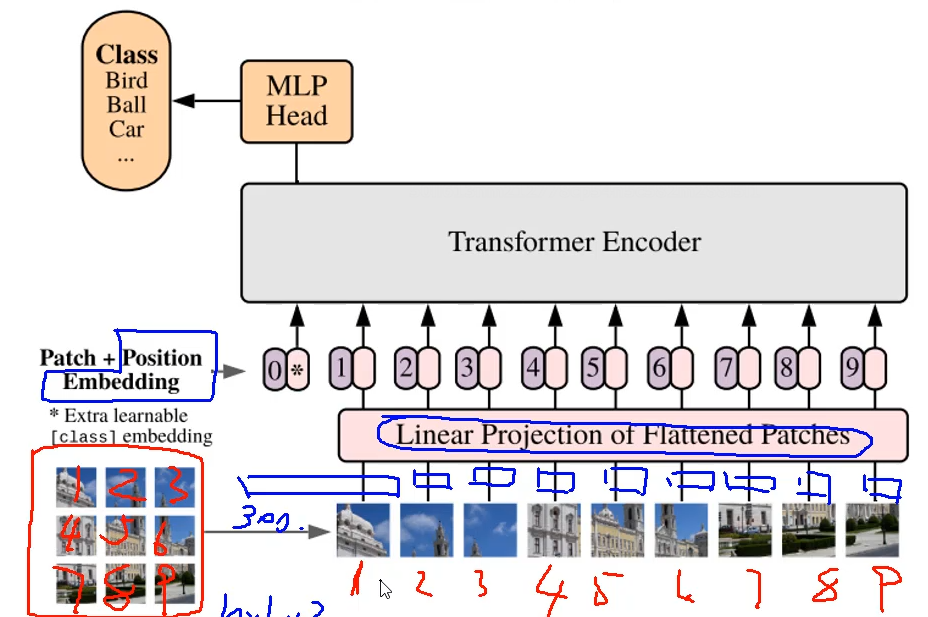
整体架构分析
将图片分割成若干块,再展开为一个向量
对于图像分类任务,可以加一个0向量,最后一层该向量的输出作全连接即可
CNN缺点
想要获得大的感受野(全局的信息)就必须堆叠很多层卷积!
这问题就来了,不断卷积+池化的操作感觉有点麻烦还不一定好
transformer根本不需要堆叠,直接就可以获得全局信息(缺点:比较吃数据)
计算公式

关于位置编码
对于图像分类任务,编码有用,但是怎么编码影响不大
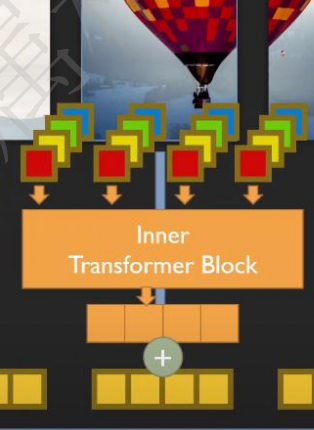
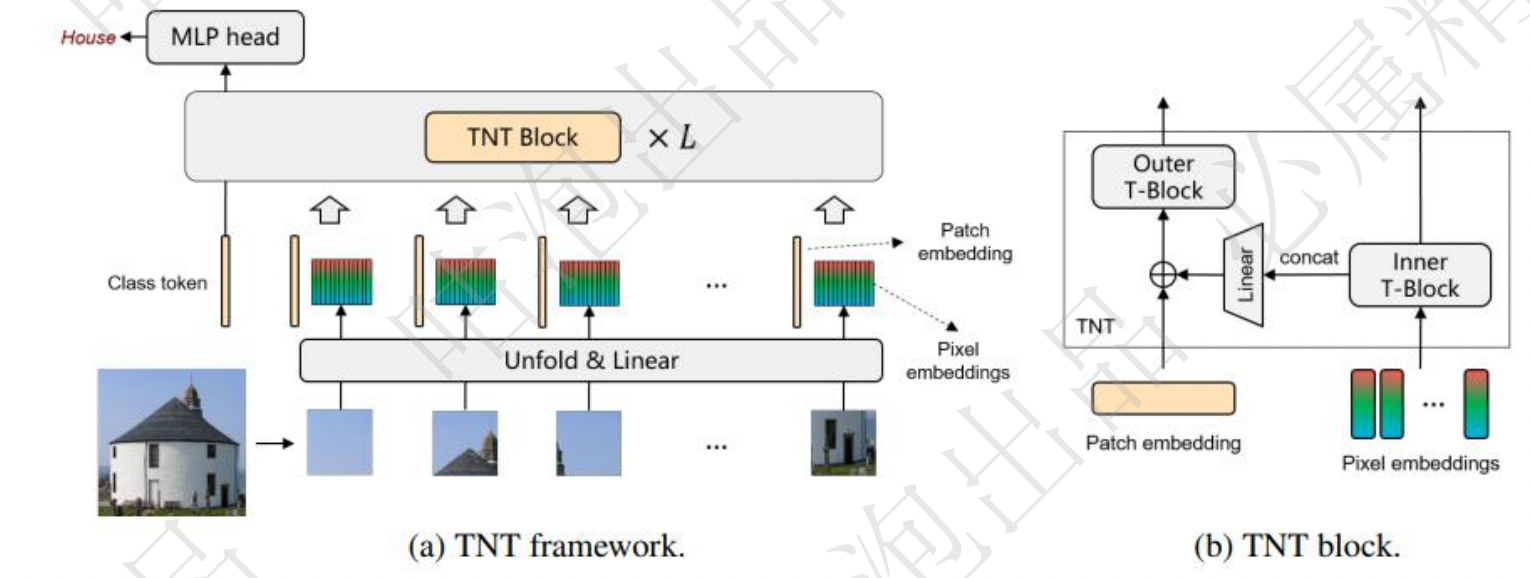
TNT:Transformer in Transformer
VIT中只针对pathch进行建模,忽略了其中更小的细节
外部transformer处理序列。(一模一样)
内部transformer:
重组成多个超像素(4个像素点)
把重组的序列继续做transformer
- 内部transformer重组成新的向量:
- 新向量再通过全连接改变输出特征大小
- 内部组合后的向量与patch编码大小相同
- 最后与原始输入pathch向量进行相加
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 魔法使いの秘密基地!
相关推荐





评论
最新文章


