
自监督——MAE
自监督
对比学习
生成式
SimMIM
- 随机mask
- Prediction haeds只需要一层全连接即可
- Prediction targets 最朴素的 L1
MAE概述
MAE 的做法可以用一句话概述:以一定比例随机 mask 掉图片中的一些图像块(patch)然后重建这些部分的像素值。
主要特点有两个:
- 非对称的编、解码器设计
- 使用较高(如 75%)的掩码率(mask 比例)
Encoder 通常是多层堆叠的 Transformer,而 Decoder 仅需较少层甚至1层
MAE 的方法属于 掩码自编码(Masked Autoencoding) 范畴,这种这玩法在 NLP 尤为火热,大名鼎鼎的 BERT 在预训练中就是这么玩的:以一定比例 mask 掉输入文本中的一些部分,让模型去预测这批被 mask 掉的内容。
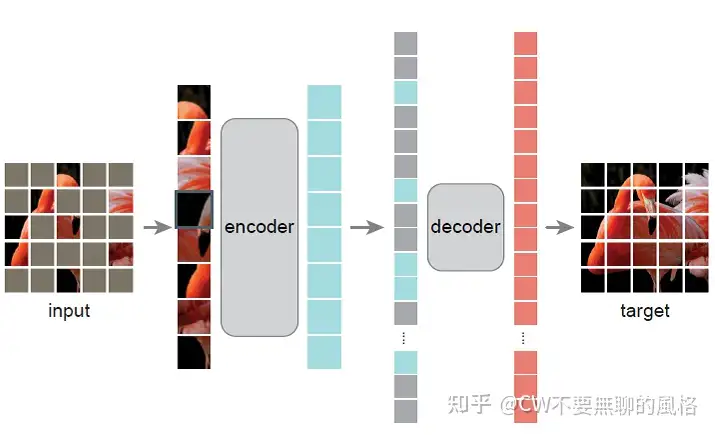
Mask 策略
首先,沿袭 ViT 的做法,将图像分成一块块(ViT 中是 16x16 大小)不重叠的 patch,然后使用服从均匀分布(uniform distribution)的采样策略对这些 patches 随机采样一部分,同时 mask 掉余下的另一部分。被 mask 掉的 patches 占所有 patches 的大部分(实验效果发现最好的比例是 75%),它们不会输入到 Encoder。
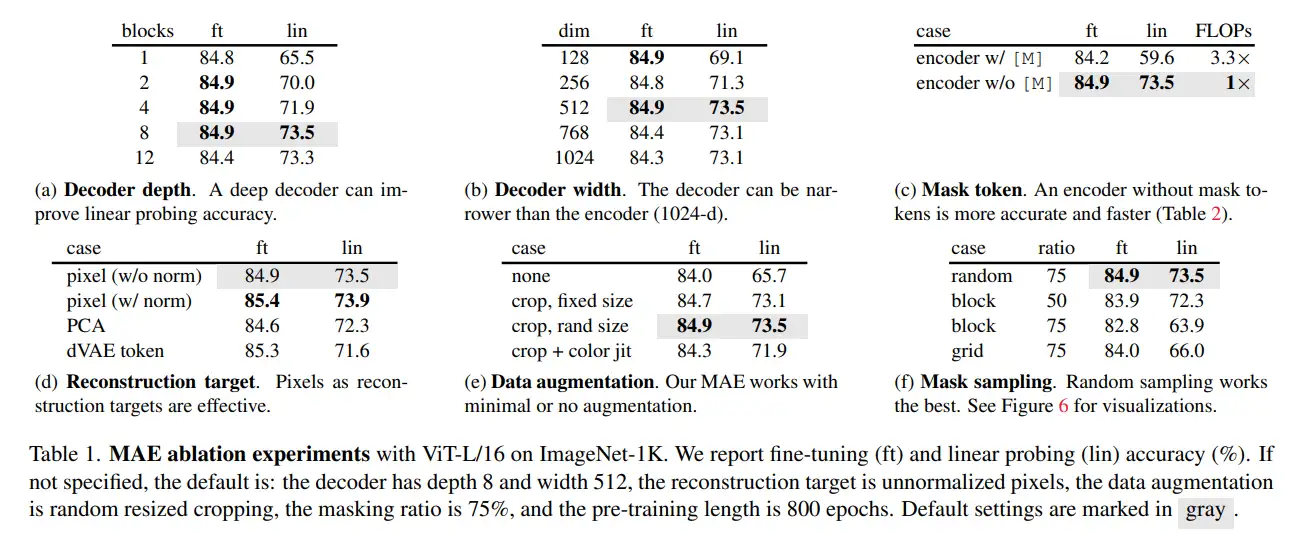
消融实验
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 魔法使いの秘密基地!
相关推荐





评论
最新文章


