
目标检测相关摘录
RetinaNet
针对现有单阶段法(one-stage)目标检测模型中前景(positive)和背景(negatives)类别的不平衡问题,提出了一种叫做Focal Loss的损失函数,用来降低大量easy negatives在标准交叉熵中所占权重(提高hard negatives所占权重)
pvtv2
pvt
https://zhuanlan.zhihu.com/p/360563672
自从ViT在图像分类中取得效果之后,关于vision transformer的研究呈井喷式爆发,PVT将ViT应用在其它图像任务中(如分割和检测),PVT相比ViT引入了和CNN类似的金字塔结构,使得PVT像CNN那样作为backbone应用在dense prediction任务。
CNN结构常用的是一种金字塔架构。这主要有两个方面的考虑,一是采用stride=2的卷积或者池化层对特征降维可以增大感受野,另外也可以减少计算量,但同时空间上的损失用channel维度的增加来弥补。
但是ViT本身就是全局感受野,所以ViT就比较简单直接了,直接将输入图像tokens化后就不断堆积相同的transformer encoders,这应用在图像分类上是没有太大的问题。但是如果应用在密集任务上,会遇到问题:一是分割和检测往往需要较大的分辨率输入,当输入图像增大时,ViT的计算量会急剧上升;二是ViT直接采用较大patchs进行token化,如采用16x16大小那么得到的粗粒度特征,对密集任务来说损失较大。这正是PVT想要解决的问题,PVT采用和CNN类似的架构,将网络分成不同的stages,每个stage相比之前的stage特征图的维度是减半的,这意味着tokens数量减少4倍,具体结构如下
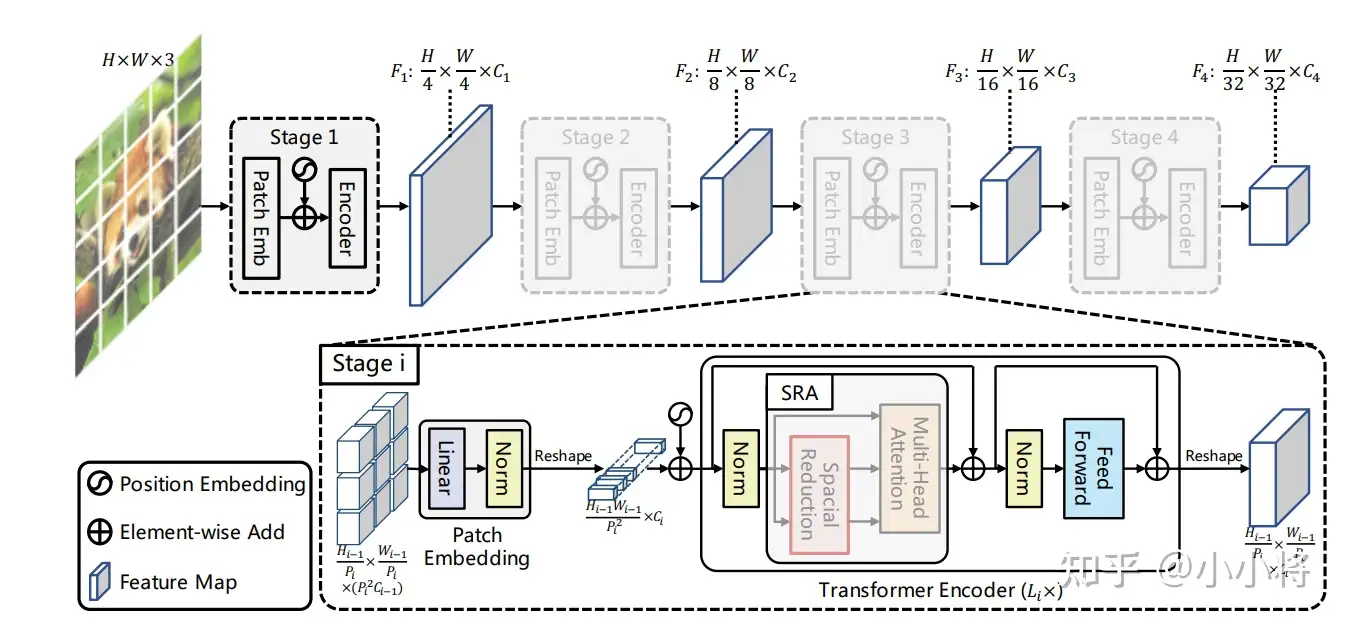
v2
https://blog.csdn.net/amusi1994/article/details/118347905
PVTv1 有三个缺点:
- 把图片当成是non-overlapping patches的序列,一定程度上丢失了图像的局部联系。
- PVTv1的position encoding是固定大小的,对处理任意图片大小不灵活。
- 当处理大分辨率的输入图像时候,计算发杂度相对较高。
pvtv2:
- 采用卷积提取局部连续特征;
- 带
zero-padding的位置编码; - 带均值池化的线性复杂度的注意力层。
组合上述三点改进即得到了本文的PVTv2,它具有以下三个特性:
- 包含图像/特征更多的局部连续性;
- 更灵活的处理可变分辨率图像;
- 具有类似CNN的线性复杂度。
类似ViT,PVTv1同样将图像视作非重叠块序列,而这种处理方式会在一定程度上破坏图像的局部连续性。此外,PVTv1中采用了定长位置编码,这对于任意尺度图像处理不够灵活。这些问题均限制了PVTv1在视觉任务方面的性能。
带zero-padding的位置编码;
下图对比了PVTv1与PVTv2在块嵌入方面的差异示意图。也就是说,在PVTv2中,我们采用重叠块嵌入对图像进行序列化。下上图a为例,我们扩大了块窗口,使得近邻窗口重叠一半面积。在这里,我们采用带zero-padding的卷积实现重叠块嵌入。
受启发于LocalViT、CPVT,我们移除了定长位置编码,将zero-padding位置编码引入到PVT,见上图b。我们采用了 深度卷积、全连接层以及GELU构建了前馈网络。
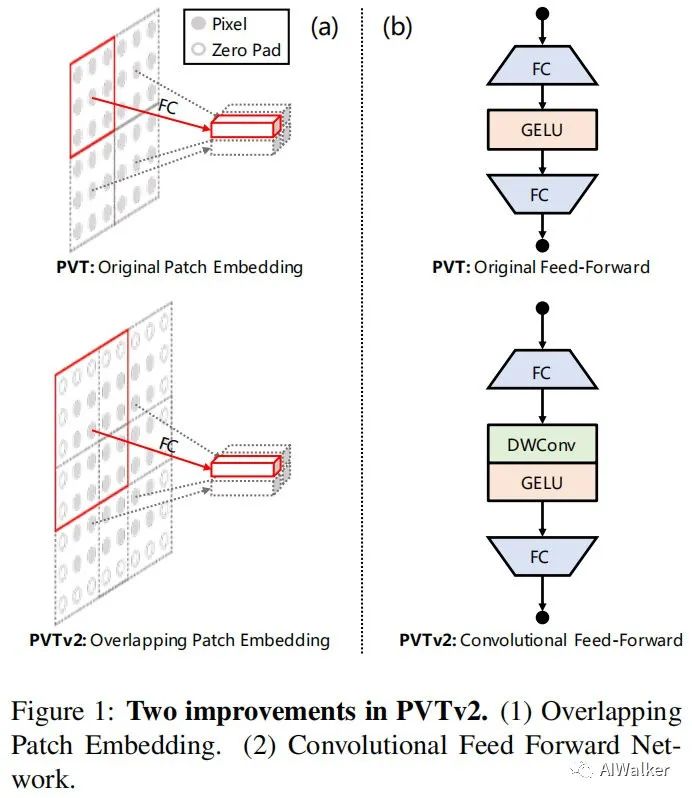
带均值池化的线性复杂度的注意力层。
为进一步减少PVT的计算量,我们提出了LSRA(Linear Spatial Reduction Attention),见上图。与SRA不同之处,LSRA具有线性复杂度、内存占用与卷积类似。具体来说,给定 的输如,SRA与LSRA的复杂度分别如下:

carafe
https://zhuanlan.zhihu.com/p/76063768
上采样操作是各种网络结构里广泛使用的运算之一,我们提出了一个轻量级的通用上采样算子 CARAFE(音[kə’ræf]),相对最近邻和双线性等上采样算子,在不同任务中都取得了显著的提升,同时只引入很少的参数量和计算代价。
其他上采样方法的不足
- 最近邻或者双线性上采样
仅通过像素点的空间位置来决定上采样核,并没有利用到特征图的语义信息,可以看作是一种“均匀”的上采样,而且感知域通常都很小(最近邻 1x1,双线性 2x2); - Deconvolution
上采样核并不是通过像素间的距离计算,而是通过网络学出来的,但对于特征图每个位置都是应用相同的上采样核,不能捕捉到特征图内容的信息,另外引入了大量参数和计算量,尤其是当上采样核尺寸较大的时候; - Dynamic filter
对于特征图每个位置都会预测一组不同的上采样核,但是参数量和计算量更加爆炸,而且公认比较难学习;
优点
- 感受野大。不同于以往只利用亚像素邻域的工作(如双线性插值),CARAFE可以在一个大的接收域中聚合上下文信息。
- 内容感知。CARAFE不是为所有的样本使用一个固定的内核(例如反卷积),而是支持特定于实例的内容感知处理,它可以动态地生成自适应的内核。
- 轻量级、计算速度快。CARAFE引入了很少的计算开销,可以很容易地集成到现有的网络架构中
cutout
Cutout的出发点和随机擦除一样,也是模拟遮挡,目的是提高泛化能力,实现上比Random Erasing简单,随机选择一个固定大小的正方形区域,然后采用全0填充就OK了,当然为了避免填充0值对训练的影响,应该要对数据进行中心归一化操作,norm到0。
出发点
- 这种操作相当于连续的dropout,只是后者是对神经元操作而且是离散的,而cutout是操作输入像素而且连续,可以减少噪声。
- 作为一个正则化方法,防止过拟合。cutcout方法很简单,就是在训练的时候,在随机位置应用一个方形矩阵。作者认为这种技术鼓励网络去利用整个图片的信息,而不是依赖于小部分特定的视觉特征。
- 通过patch的遮盖让网络学习到遮挡的特征。cutout不仅能够让模型学习到如何辨别他们,同时还能更好地结合上下文从而关注一些局部次要的特征
作者发现cutout区域的大小比形状重要。
- 正方形区域的边长固定;
- 正方形区域使用同一种像素值填充;
- 正方形随机出现在图片中,超出边界的部分被截断;
要注意:
- 正方形边长的设定,是否会覆盖图像主要信息;在尺度不一的实际业务场景中可能影响其效果,比如目标检测中将目标全部覆盖了。
- 使用Cutout前,先进行归一化;以降低像素填充的影响







