
SAR图像变化检测深度学习研究方法
概述
一般方法
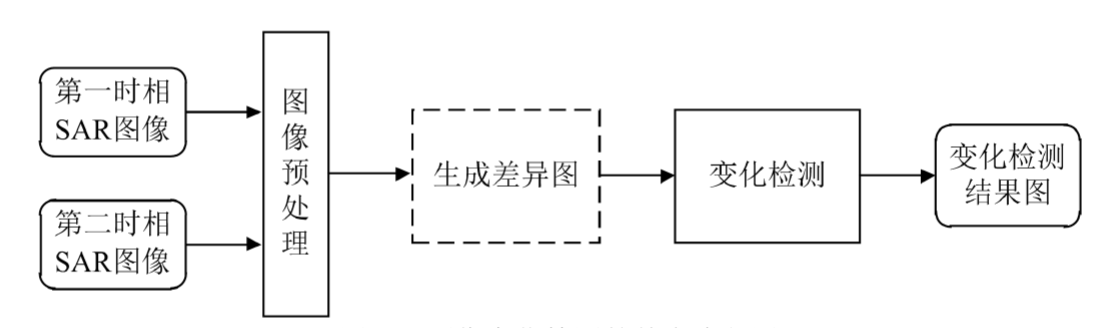
第一步,在进行变化检测之前需要对两幅图像进行几何校正、辐射校正以及去噪
等预处理操作。
- 几何校正是指SAR成像过程中,由于传感器姿态、地球旋转等条件的影响会使原始图像上地物的特征与其对应的地面地物的特征发生几何畸变, 所以在变化检测之前需要对图像执行几何校正操作。
- 辐射校正是指图像在获取、传输过程中会发生辐射失真的现象,因此在图像预处理的过程中有必要进行辐射校正。
- 图像去噪是指SAR传感器在成像过程中会被相干斑噪声干扰,导致获取的图像不能准 确而真实的反映出地物信息,故在SAR图像变化检测之前有必要对相干斑噪声进行滤除。
第二步,生成差异图是指对两幅SAR图像进行某种操作从而生成为一幅图像 的过程。值得注意的是生成差异图这一步骤在SAR图像变化检测中并不是不可或缺的(该步骤表示为虚线框),经过近年来的研究可知,变化信息可以通过直接对预处理后的图像进行操作来获得。
第三步,采用变化检测算法对差异图或预处理之后的图像以有监督或无监督的方式进行分类,进而得到变化检测结果图
评价指标
假设,在变化检测结果图中,实际发生变化但检测为未变化的像素点数为Cu, 实际未发生变化但检测为变化的像素点数为Uc,实际未发生变化且检测为未变化的像素点数为Uu,实际发生变化且检测为变化的像素点数为Cc
漏检数False Negatives,FN = Cu
错检数(False Positives,FP = Uc
总错误数(Overall Errors, OE = FN+FP
正确检测率(Percentage Correct Classification,PCC = (Uu+Cc)/(Uu+Cc+Cu+Uc)
Kappa系数Kappa Coefficient,KC = (PCC - PRE)/(1-PRE)
其中
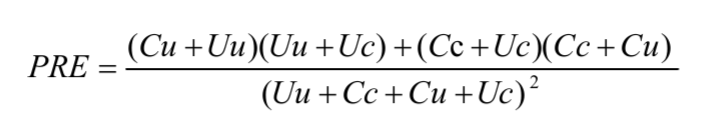
目前存在的问题
SAR图像存在斑点噪声
训练样本有限
获得的伪标签通常存在误差
网络上的固有问题
深度学习方法(至2020年):https://blog.csdn.net/qq_39932172/article/details/114452418
基于双路径去噪网络的SAR图像变化检测 2021
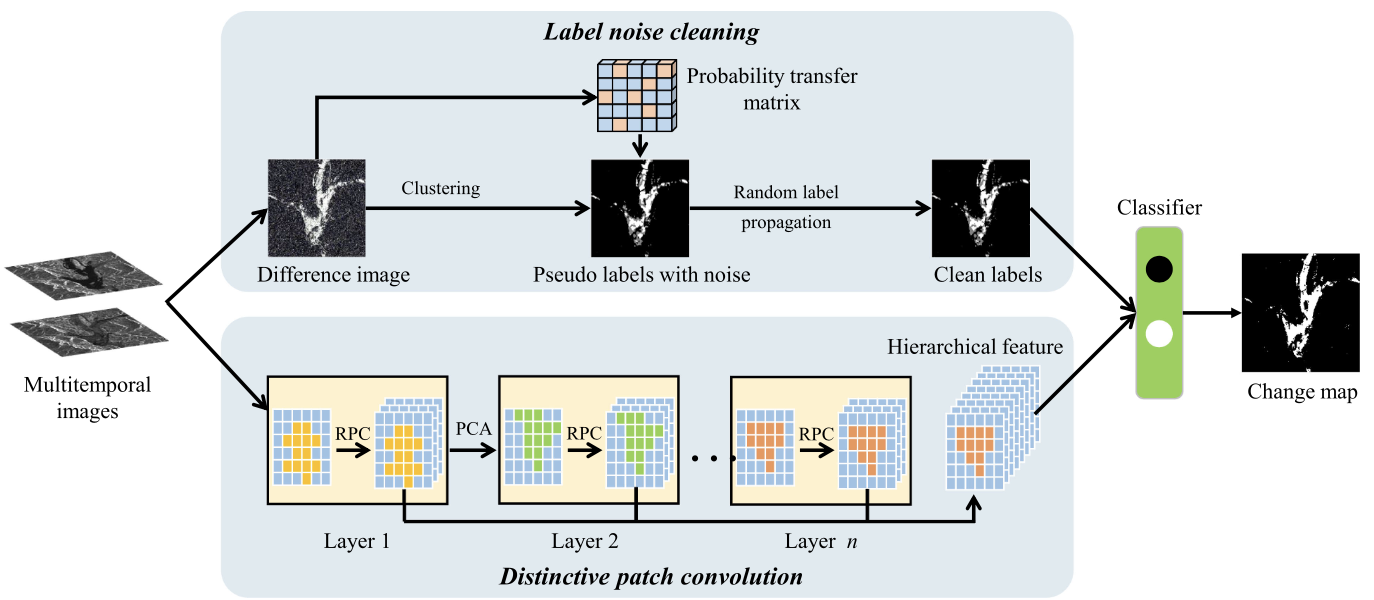
一个分支采用随机标签传播来消除预分类中产生的标签噪声。另一个分支是通过叠加多个卷积层来提取浅层和深层特征。最后,将清洁标签和堆叠特征输入分类器,计算最终的变化检测结果
解决的问题
1)获得的伪标签通常存在误差。
DPDNet的一个分支使用随机标签传播来清除标签噪声。此外,DPDNet的另一个分支用于提取浅层特征和深层特征,然后将它们组合在一起进行分层特征表示。
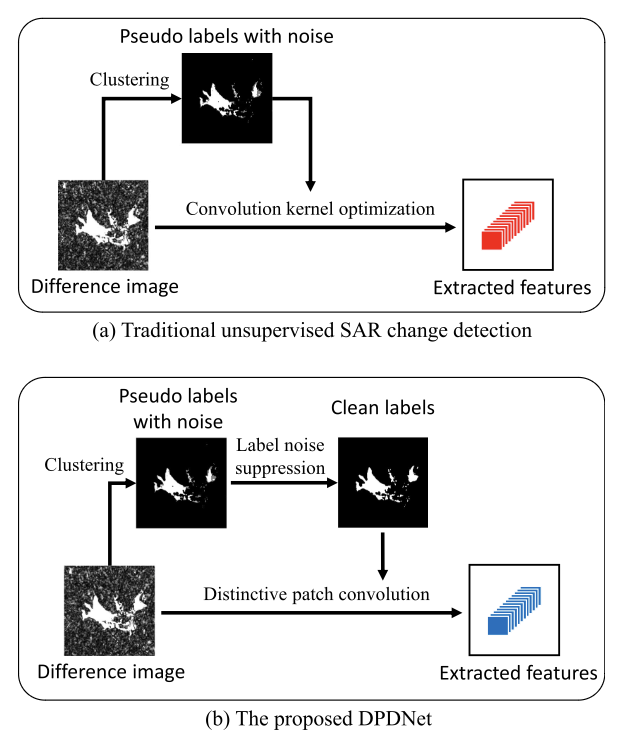
2)基于深度学习的方法在训练阶段非常耗时。缺乏大量可靠样本。
主要贡献
- 首次尝试同时解决散斑噪声和标签噪声的问题。以往的工作主要集中在散斑噪声方面。然而,标签噪声问题不利于变化检测的性能。所提出的DPDNet可以同时缓解两种噪声,并生成更精确的变化图。
- 提出了一种新的独特的补丁卷积(DPConv),它简化了网络结构,加快了训练阶段。从原始图像中提取的patch被用作卷积核,因此参数优化不需要太多的训练样本。
基于层注意容噪网络的SAR图像变化检测2022
提出了一种基于层注意的噪声容忍网络, LANT-Net,它互连卷积层并且对噪声标签不太敏感。
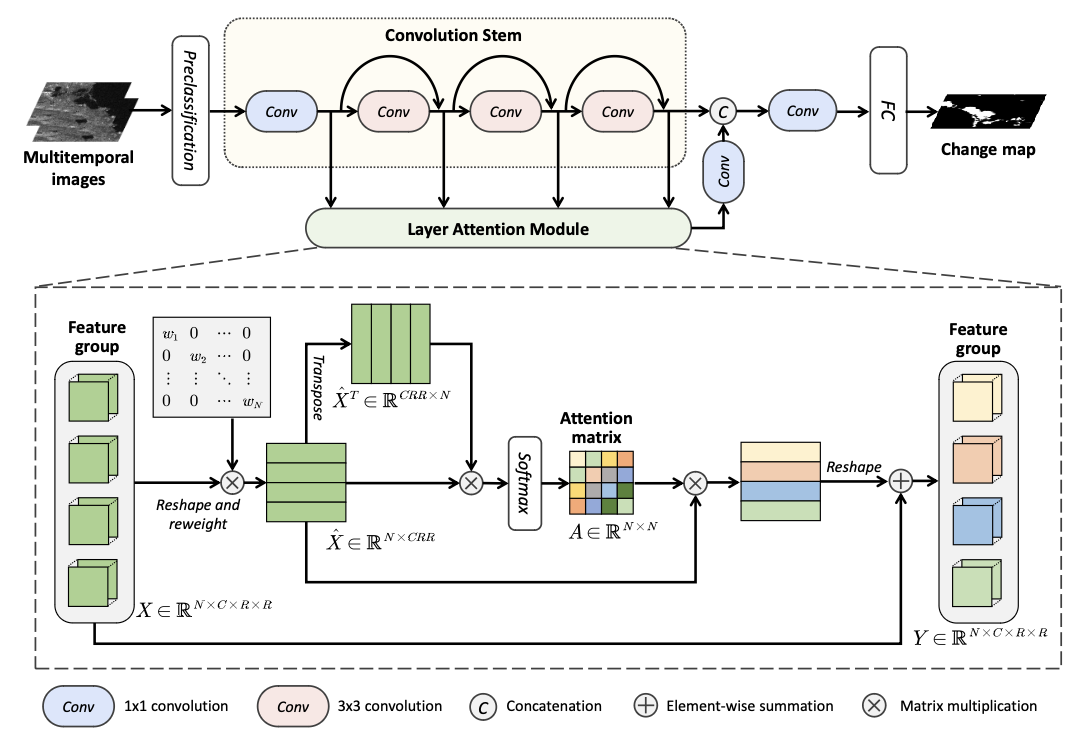
设计了一个用于变化检测的层注意模块,它自适应地对来自不同层的特征进行加权。此外,设计了一个可以有效抑制噪声标签影响的噪声容忍损失函数。它结合了交叉熵 (CE) 损失和平均绝对误差 (MAE)。因此,网络对噪声标签不太敏感并且收敛速度快。
解决的问题
- 卷积层之间的特征交互。现有的自注意力增强 CNN 通常在卷积层之后包含一个注意力块,它忽略了多层卷积之间的相互作用。鉴于此,探索卷积层之间的信息流至关重要。
- 伪标签中涉及的错误。现有的无监督变化检测方法通常使用聚类来生成具有高训练置信度的伪标签。然而,错误参与伪标签限制网络优化。因此,为无监督变化检测任务建立一个噪声容忍模型是至关重要的。
主要贡献
提出了一个层注意模块,它利用了多层卷积的相关性。来自不同卷积层的特征相互协作,有效地提高了网络的表示能力。
引入了噪声容忍损失函数来减轻伪标记样本中噪声标签的影响。它使模型对噪声标签不那么敏感,收敛速度快。
- 代码开源
技术细节
LANTNet 包括三个组件:预分类模块、卷积干和层注意模块。
预分类使用ratio operator 和 the hierarchical Fuzzy C-Means。将I1、I2、差异图像拼接成3 × R × R,作为输入
卷积干由四个卷积层组成,第一个1*1通道数16,然后三个3*3通道数32,中途生成的特征组合起来,并送入层注意力模块。
层注意模块
输入X,维度N*C*R*R,N为4(卷积数),C在代码中为32,reshape为N*CRR。
随后,用矩阵乘法将对角矩阵W与特征图相乘,来加权来自不同层的特征。(W被初始化为单位矩阵)结果记为X^
然后计算注意力矩阵A。⊗表示矩阵乘法
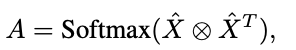
将X^乘以A,reshape为N*C*R*R。与X相加,得到Y。其中φ表示reshape操作。
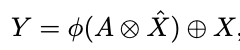
最后通过1*1卷积,FC层,Softmax回归,得到结果。
损失函数
{(xi, yi)|1 ≤ i ≤ m} , 其中xi是输入图像补丁,yi是与xi相关的标签,m是样本总数
平均绝对误差 (MAE) Loss,其中f(·)表示网络,ey是one-hot向量

交叉熵 (CE) Loss
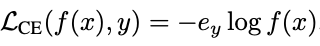
结合起来,α设置为0.1,β设置为0.9
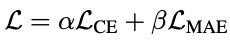
数据集和评价指标
第一个数据集为巢湖数据集,大小为384 × 384像素。这颗卫星分别于2020年5月和7月在中国被Sentinel-1传感器捕获。第二个数据集是渥太华数据集,大小为290 × 350像素,分别由Radarsat传感器于1997年5月和8月获取。渥太华数据集显示了受洪水影响的变化地区。第三个数据集是苏兹伯格数据集,由欧洲航天局的Envisat卫星于2011年3月11日和16日捕获。这两张照片都显示了海啸引起的冰架破裂
采用假阳性(FP)、假阴性(FN)、总体误差(OE)、正确分类率(PCC)和Kappa系数(KC)五个常用的评价指标对变化检测性能进行评价。
代码实现
https://github.com/summitgao/LANTNet
1 | import numpy as np |
定义相关函数
1 | def image_normalize(data): |
得到训练和测试数据
1 | # read image, and then tranform to float32 |
得到train_loader
1 | """ Training dataset""" |
层注意力
1 | # 层注意力 |
Loss
1 | # 噪声鲁棒的损失函数 |
LANTNet网络
1 | class LANTNet(nn.Module): |
训练
1 | # 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 |
检验
1 | # 逐像素预测类别 |
基于双域网络的SAR图像变化检测2022
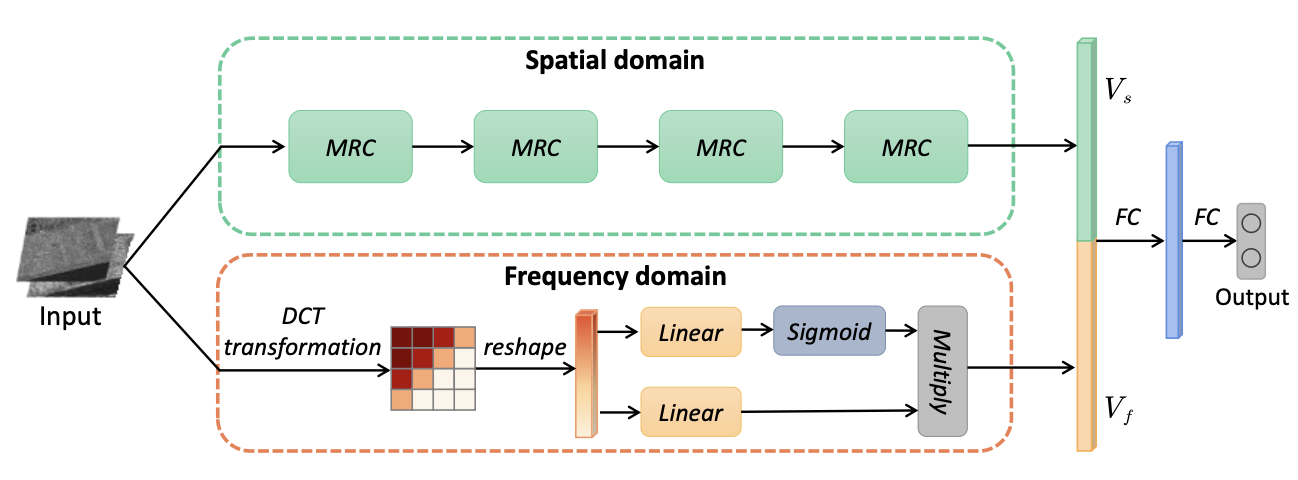
该网络由两个分支组成:一个是用于捕获多区域特征的空间域分支,一个是用于编码DCT系数的频域分支。在空间域分支中,该网络包含四个MRC模块,能够在保留上下文信息的同时强调中心区域特征。在频域分支中,将输入图像补丁通过DCT转换到频域,然后通过“开关”选择DCT系数的关键分量。
解决的问题
现有的方法主要集中在空间域的特征提取上,对频域的特征提取较少关注。
在patch特征分析中,边缘区域可能引入一些噪声特征。
主要贡献
- 第一个引入DCT域的特征来解决SAR图像变化检测问题。利用了频域和空间两方面的特征。因此,可以有效地抑制散斑噪声
- 提出了一个MRC模块,它联合强调每个图像补丁的中心区域,同时保留上下文信息。对中心区域特征和上下文信息进行自适应组织以完成分类任务。








